Web Scraping in 2024: A Beginner’s Guide

A New Era
Web scraping has been around for a long time but it has become more important than ever in recent years. With the rise of AI and machine learning, web scraping has become a powerful tool for data analysis and automation. Gone are the days of being able to scrape websites with simple requests, with affordable and easily accessible defences like Cloudflare, even small apps can protect themselves from most scrapers.
That is a good thing as it turned scraping into more of anart than a science, as websites become more sophisticated and harder to scrape. the TWO MAIN KEYs in scraping are infrastructure and tactics. If you want to scrape at scale for fun or profit, keep reading.
Web Scraping == Bug Bounty Hunting
A lot of underappreciated tactics for web scraping come from bug bounty hunters. They are experts in finding vulnerabilities in websites and the tools they use can help you scrape data more effectively. Think of content discovery, proxies and infrastructure. If they can find hidden subdomains, directories and APIs so can you.
I have studied the ways of bug bounty hunters and became one myself to immerse myself in their tools and techniques, especially regarding the HOW to find hidden URLs, subdomains and data. This experience was a crash course in fuzzing, brute-forcing and treating the websites like penetration testing targets.

Infrastructure¶
INFRASTRUCTURE is the most important part of scraping. We are talking about IPs, proxies & instances.
You do not want to hit the website with the same IP address a bajillion times. At that point you are just asking for a ban (which is very easy to ban an IP). A trick I found while doing large-scale scraping for clients is to set up cheap EC2 instances or whatever provider you use, each running Playwright. You NEED distributed IPs and EC2 instances in order to scrape at scale.
Heres the key though, seperate your discovery infastructure from you actual scraping infrastructure.
What this means is to find your ‘target’ using one set of tools, then scrape using another. This keeps you from getting flagged too early and helps you stay under the radar. REMEMBER, while it is easy to go full ape mode and scrape aggressively, this is will look a lot like a DDoS attack-like a planet of the apes type DDoS attack

Be Chill
Just because you can scrape a website, does not mean you should do it carelessly. Randomize your activity, throw in random pauses and DO NOT OVERWHELM SOMEONE’S INFRASTRUCTURE. Sure it might be legal to scrape public data, but don’t be reckless and ruin it for everyone. So be smart, respect the ecosystem and avoid setting off alarms. We don’t want to be a jerk, as we are walking a fine line between a penetration test and scraping. Always follow the TOS and NEVER BREAK THE RULES.
Actual Scraping and Infra
If I get enough feedback I might write part 2, but her is what a cheap infra could look like.
Content Discovery flow
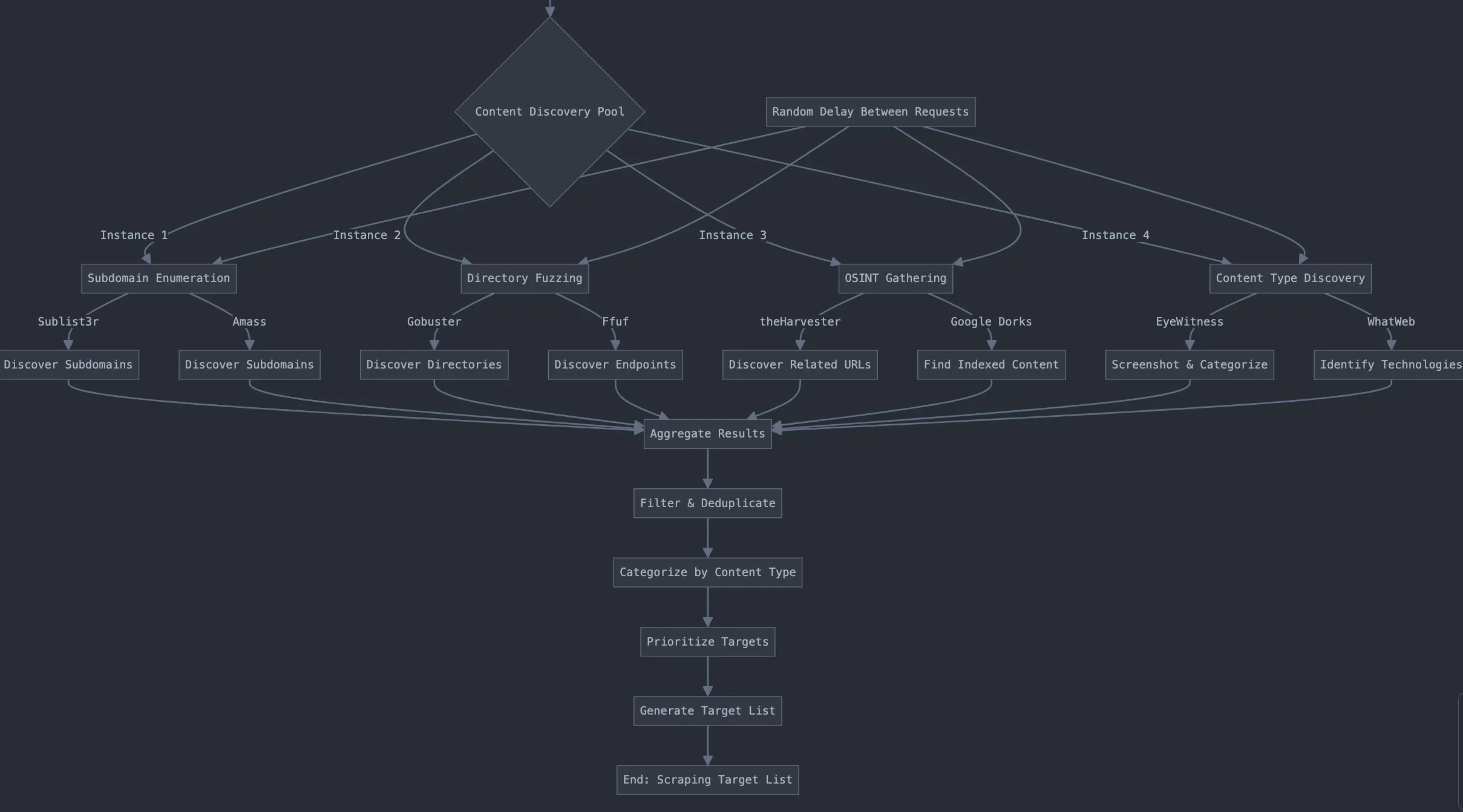
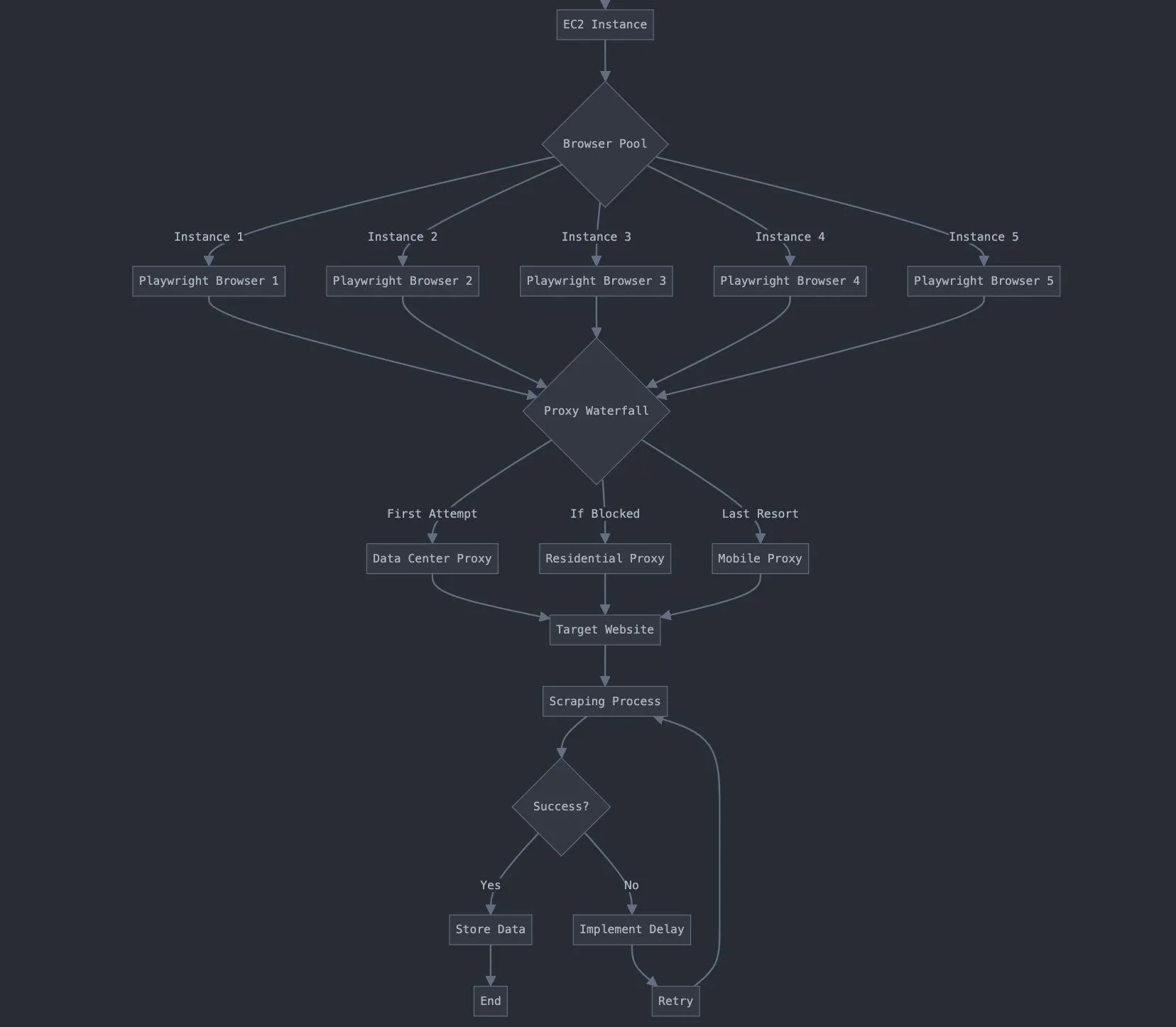
Scraping flow
Scraping Code
### First prep script
import asyncio
from playwright.async_api import async_playwright
import random
import json
async def scrape_with_playwright(url):
async with async_playwright() as p:
browser = None
try:
browser = await p.chromium.launch()
context = await browser.new_context(
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.124 Safari/537.36'
)
page = await context.new_page()
await page.set_extra_http_headers({
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept': ('text/html,application/xhtml+xml,application/xml;q=0.9,'
'image/avif,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3;q=0.9'),
})
await page.goto(url)
delay = random.uniform(0.8, 2)
await asyncio.sleep(delay)
content = await page.content()
print(f"Successfully scraped {url}")
return content
except Exception as e:
print(f"Error scraping {url}: {str(e)}")
return None
finally:
if browser:
await browser.close()
async def main():
url = 'https://example.com'
content = await scrape_with_playwright(url)
if content:
with open('result.json', 'w', encoding='utf-8') as f:
json.dump({'url': url, 'content': content}, f, ensure_ascii=False)
print('Content saved to result.json')
else:
print('No content to save')
asyncio.run(main())
###2nd
import asyncio
from playwright.async_api import async_playwright
import json
async def create_browser_pool(pool_size):
playwright = await async_playwright().start()
browsers = []
for _ in range(pool_size):
browser = await playwright.chromium.launch()
browsers.append(browser)
semaphore = asyncio.Semaphore(pool_size)
return playwright, browsers, semaphore
async def close_browser_pool(playwright, browsers):
for browser in browsers:
await browser.close()
await playwright.stop()
async def get_browser(browsers, semaphore):
await semaphore.acquire()
return browsers.pop()
async def release_browser(browser, browsers, semaphore):
browsers.append(browser)
semaphore.release()
async def scrape_url(browsers, semaphore, url):
browser = await get_browser(browsers, semaphore)
try:
page = await browser.new_page()
await page.goto(url)
content = await page.content()
print(f"Scraped {url}")
return {'url': url, 'content': content}
except Exception as e:
print(f"Error scraping {url}: {str(e)}")
return {'url': url, 'error': str(e)}
finally:
await release_browser(browser, browsers, semaphore)
async def main():
urls = [
'https://example.com',
'https://example.org',
'https://example.net',
'https://example.edu',
'https://example.io'
]
pool_size = 3
playwright, browsers, semaphore = await create_browser_pool(pool_size)
try:
tasks = [scrape_url(browsers, semaphore, url) for url in urls]
results = await asyncio.gather(*tasks)
finally:
await close_browser_pool(playwright, browsers)
with open('results.json', 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False)
for result in results:
url = result.get('url')
content = result.get('content')
if content:
print(f"Result for {url}: {content[:50]}...")
else:
print(f"No result for {url}, error: {result.get('error')}")
asyncio.run(main())
Subdomain tools
- Sublist3r - Fast subdomains enumeration tool
- MassDNS - High-performance DNS stub resolver
- Sudomy - Subdomain enumeration and analysis tool
Content Discovery Tools
